
Who is Brett Adcock and Why Does This Prediction Matter?
Brett Adcock isn't just another tech founder making bold claims on LinkedIn. He's a serial entrepreneur who previously founded Archer Aviation (an electric air taxi company now publicly traded) and Vettery (a hiring marketplace acquired for $100M+). In 2022, he founded Figure AI with a singular mission: build the world's first commercially viable humanoid robot.

Figure AI's trajectory has been remarkable:
- Founded in 2022, demonstrated their first walking robot within 12 months
- Raised over $750 million from OpenAI, Microsoft, NVIDIA, Jeff Bezos, and Intel
- Valued at approximately $2.6 billion (with reports of seeking $40B valuation in 2025)
- Became the first company to deploy a humanoid robot in a real production environment (BMW's Spartanburg plant)
- Released Helix, arguably the most advanced Vision-Language-Action model for humanoid control
So when Brett makes a prediction about where humanoid robotics will be in 12 months, it carries weight. He has skin in the game, access to cutting-edge research, and a track record of executing on ambitious timelines.
But here's the tension: Founders are incentivized to be optimistic. Their job is to paint a vision that attracts talent, capital, and customers. The question we need to answer is, does the current state of technology support this timeline, or is this aspirational storytelling?
This is a bold prediction from Brett Adcock so Let's break down every technical concept in his prediction and then assess where we actually stand.
Breaking Down the Prediction
"Unsupervised, multi-day tasks" This means robots operating autonomously for extended periods (days, not minutes) without a human watching over them or correcting mistakes. Currently, most robot demonstrations last minutes to hours with significant human oversight.
"Homes they've never seen before" This is about generalization, the robot's ability to transfer learned skills to completely novel environments. Your kitchen is different from my kitchen (different layouts, objects, lighting), yet the robot should handle both without retraining.
"Driven entirely by neural networks" This means no traditional robotics stack, no hand-coded motion planners, no explicit state machines, no manual trajectory optimization. Pure learned behavior from data.
"Pixels to torques" This is the key technical phrase. Let me explain:

"Pixels to torques" describes an end-to-end system where a single neural network takes in raw images and directly outputs motor commands, no intermediate representations designed by humans.
"Long time horizons" This refers to temporal abstraction, the ability to plan and execute sequences of actions that unfold over hours or days, not just seconds. Making a meal requires hundreds of coordinated sub-tasks.
Current State of the Art (Reality Check)
What Robots Can Actually Do Today
Factory Setting (Figure 02 at BMW):
- The Figure 02 robots ran 10-hour shifts Monday through Friday with 1,250 hours of runtime, loaded more than 90,000 parts and contributed to the production of over 30,000 BMW X3 vehicles. The robots performed a "classic pick-and-place task" by loading sheet metal parts from racks or bins and placing them on a welding fixture.
- The task required placing parts within a 5-millimeter tolerance in just 2 seconds. Key metrics tracked were cycle time (84 seconds total, 37 seconds load time), placement accuracy (target >99% success per shift), and interventions (goal was zero per shift).
Critical Reality Check:
- As of March 2025, only a single Figure 02 robot was operating at the plant, performing a repetitive task in the body shop. The robot retrieves metal sheet parts from a logistics container and places them onto a fixture for welding, a far cry from comprehensive "end-to-end operations."
Home Environment : The Cutting Edge
Physical Intelligence's π0.5 model exhibits meaningful generalization to entirely new environments, specifically, cleaning up a kitchen or bedroom in a new home not seen in training data. However, the company states: "Our current model is far from perfect: its goal is not to accomplish new skills or exhibit high dexterity, but to generalize to new settings."
π0: First Generalist Policy by Physical Intelligence (π)
Independent evaluations show π0 achieves only 20-50% success on simple tasks straight out of the box. Performance is sensitive to prompt phrasing, and the policy struggles with instruction following, fine-grained manipulation, and partial observability. Researchers note: "We don't expect π0 to be installed in everyone's home tomorrow."
Technical Deep Dive: How VLA Models Work
Let's look into the key architecture that makes this possible:
The "Dual-System" Architecture
This is inspired by Daniel Kahneman's "Thinking, Fast and Slow" concept:

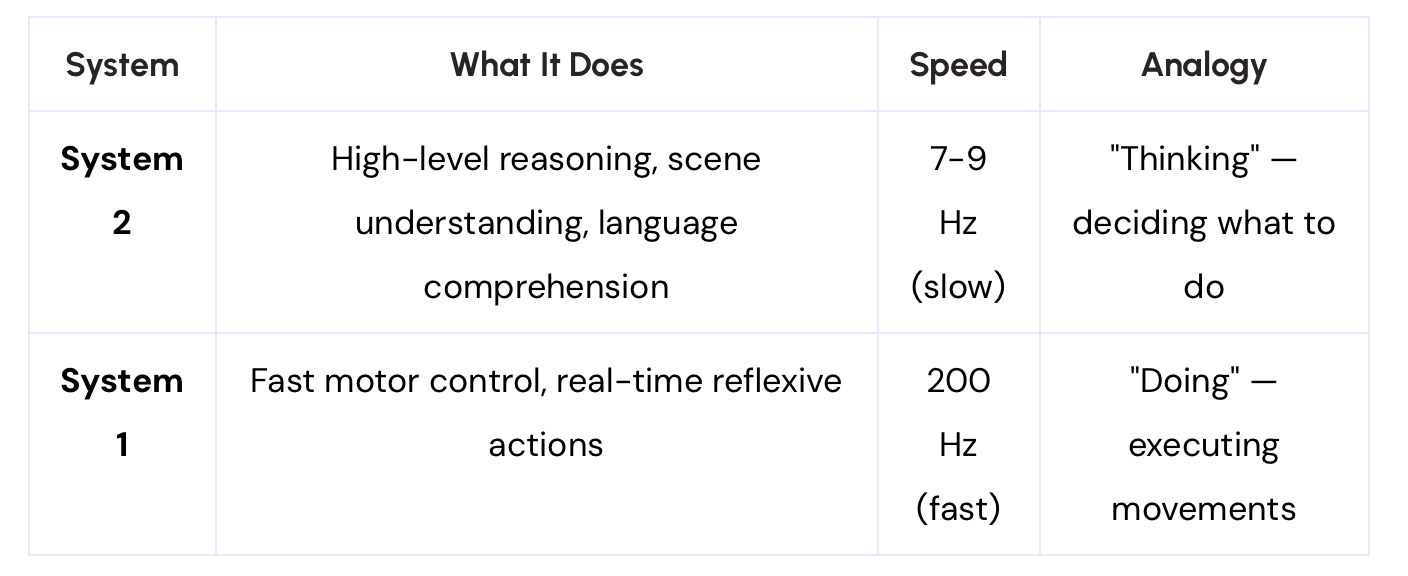
What is Hz here? Hz (Hertz) = cycles per second. 200 Hz means the motor system updates 200 times per second, fast enough for smooth, reactive movement.
Figure AI's Helix uses this architecture: System 2 is an internet-pretrained VLM operating at 7-9 Hz for scene understanding and language comprehension. System 1 is a fast reactive visuomotor policy that translates the latent semantic representations produced by S2 into precise continuous robot actions at 200 Hz. This decoupled architecture allows each system to operate at its optimal timescale, S2 can "think slow" about high-level goals, while S1 can "think fast" to execute and adjust actions in real-time.
Key Technical Terms Explained
Flow Matching (used by π0): A technique for generating smooth, continuous action trajectories. Unlike older "diffusion" methods that require many steps to generate an action, flow matching learns a direct path from noise to action, making it faster and smoother.
Think of it like:
- Diffusion: Finding your way through a maze by random wandering
- Flow Matching: Having a GPS that shows you the direct route
Action Tokenization: Converting continuous robot movements into discrete "tokens" (like words in language). This lets language models process actions the same way they process text.
End-to-End Learning: The entire pipeline, from pixels to motor commands, is one unified neural network with no hand-coded rules in between. The alternative is a "modular" approach with separate components for perception, planning, and control.
Zero-Shot Generalization: Performing tasks never seen during training, without any additional learning. This is the holy grail, a robot that "just works" in new situations.
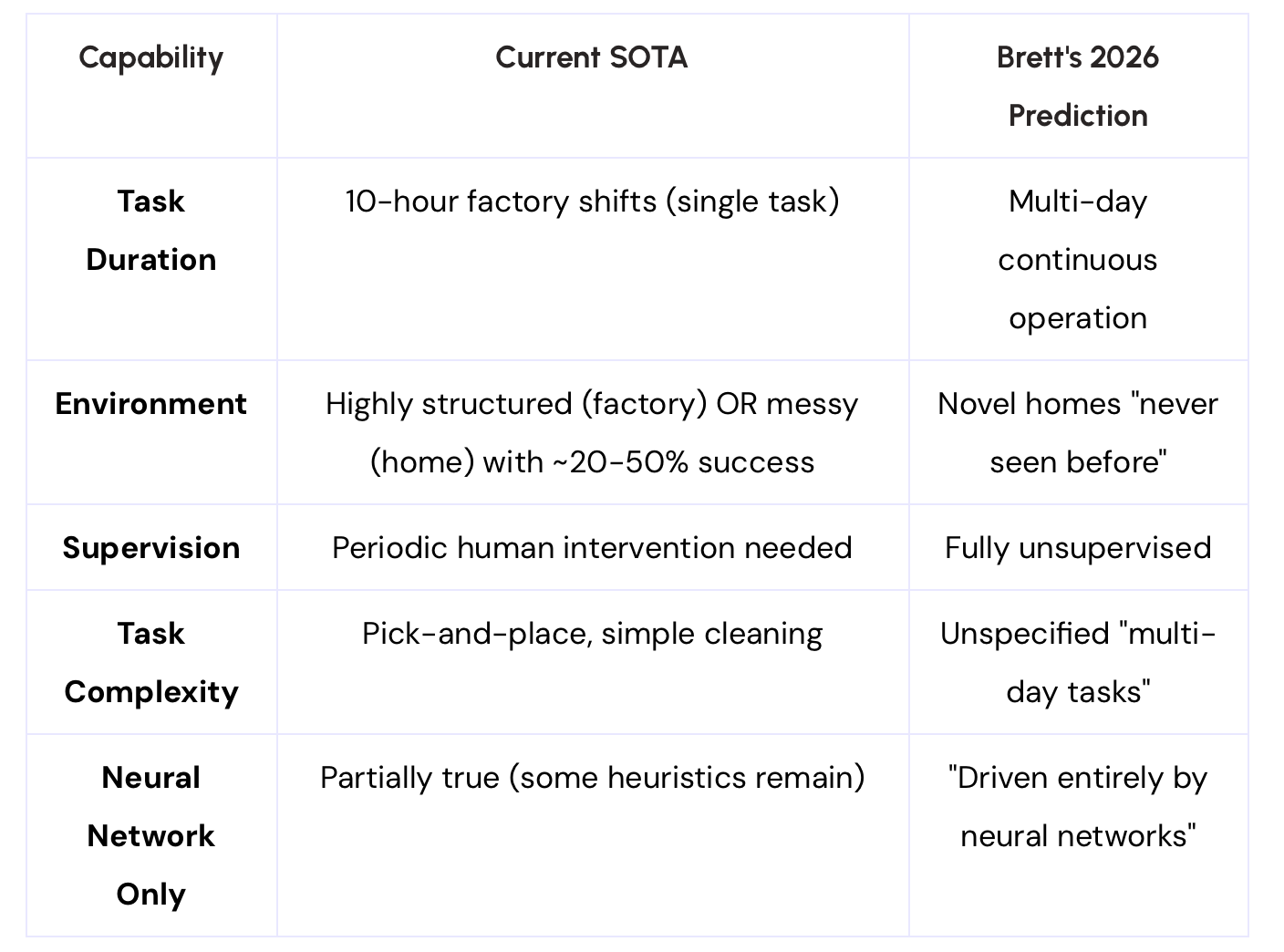
The Gap: Where We Are vs. Brett's Prediction
What "Pixels to Torques" Actually Requires
This phrase sounds simple but requires solving several hard problems:
- Temporal Credit Assignment: If a task takes hours, how does the network know which action 3 hours ago contributed to success/failure?
- Error Accumulation: Small errors compound over time. A 0.1% position error repeated 10,000 times becomes catastrophic.
- State Estimation: The robot must continuously understand where it is, where objects are, what has changed, all from cameras alone.
- Long-Horizon Planning: Planning a sequence of hundreds of subtasks while handling unexpected events.
My Assessment: Is the Prediction Realistic?
Technically Possible?, The architecture exists. Helix is the first VLA to output high-rate continuous control of the entire humanoid upper body, including wrists, torso, head, and individual fingers, and can pick up virtually any small household object including thousands of items never encountered before.
Practically Achievable by 2026? Extremely aggressive.
The current gaps are substantial:
- Home demonstrations are still tightly controlled and short-duration
- Success rates in truly novel environments hover around 20-50%
- "Multi-day" autonomy hasn't been demonstrated anywhere
Brett Adcock is making a founder prediction, optimistic by design to attract talent, investment, and attention. His company (Figure) has clear incentives to paint an ambitious picture.
My honest assessment: We'll likely see impressive 1-2 hour autonomous demonstrations in select home settings by late 2026, but "multi-day unsupervised tasks in homes they've never seen" remains aspirational, not imminent.
The rate of progress is genuinely remarkable, but Brett's timeline compresses what I'd estimate as 3-5 years of remaining work into 12 months.
