TL;DR Diffusion Policy borrows the denoising trick from Stable Diffusion (start with pure noise, gradually refine) and applies it to a short horizon of robot actions instead of pixels. It crushes classic behavior cloning baselines on manipulation benchmarks, but the sampling loop is slow and still blind to out-of-distribution situations. Recent follow-ups (OneDP, RNR-DP, Consistency Policy, Diff-DAgger) attack those pain points with distillation, smarter noise scheduling, and uncertainty heads.
Motivation & Intuition
Generative image models taught us a weird lesson: start with random static, nudge it repeatedly, beautiful pictures emerge. Cheng Chi and colleagues asked: what if a robot’s next half-second of motion is treated like that noisy canvas?
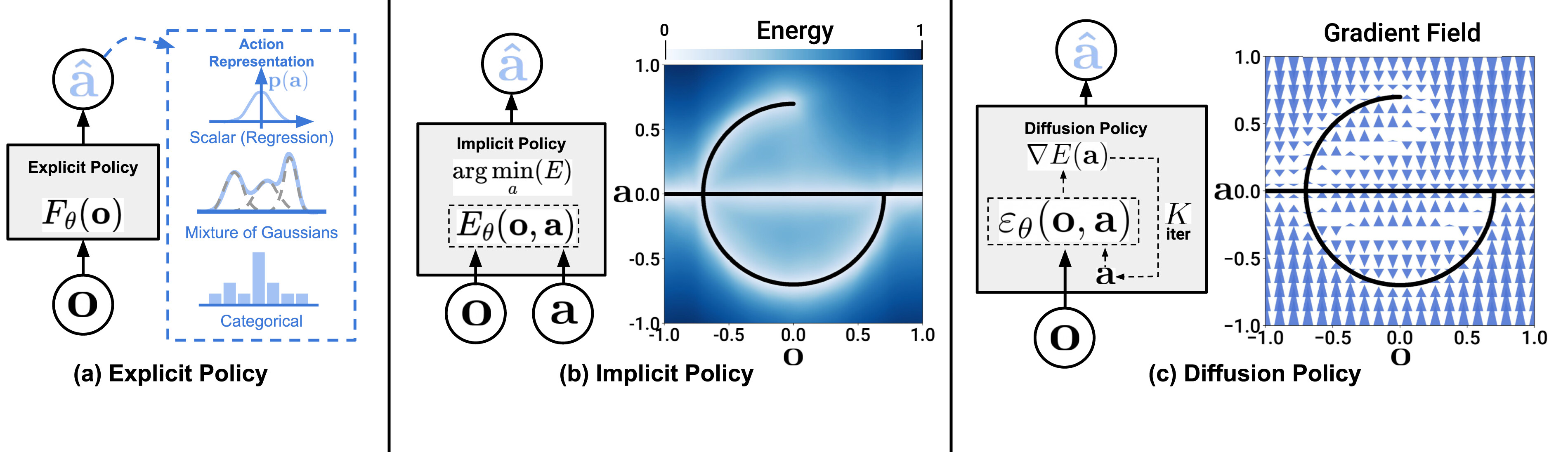
Diffusion Policy applies the same iterative denoising process used in Stable Diffusion to robot actions. Starting with random noise, the model gradually refines action trajectories conditioned on visual observations. (Source: Chi et al., ‘Diffusion Policy: Visuomotor Policy Learning via Action Diffusion’, 2023)
In plain English:
- Look at the scene through the robot’s cameras.
- Make up completely random future actions.
- Run about 30 tiny clean-up steps that steer those actions toward what human demos considered “normal” for that visual situation.
- Send only the first action to the motors; re-sense and repeat 30 ms later.
That’s Diffusion Policy (DP) in one sentence.
The Algorithm, Step by Step
| Stage | What happens | Why it matters |
|---|---|---|
| Encode observation | CNN / ViT turns RGB (optionally depth or point cloud) into a latent vector $o$ | Separates visual perception from control so only the perception backbone runs once per timestep. |
| Add action noise | Sample Gaussian noise $\epsilon \sim \mathcal{N}(0,I)$ for an $H$ step action sequence $a_{0:H-1}$ | Gives the model a trajectory canvas to sculpt. |
| Iterative denoising | For timestep $t=T \dots 1$: update $a$ with gradient step toward more likely actions given observation | Each step is a tiny gradient descent toward demo likelihood, conditioned on observation. |
| Receding horizon exec. | Take $a_{0}$, send to robot, shift horizon & refill tail with fresh noise | Keeps planning window small but ensures smoothness across iterations. |
Typical hyperparameters: $T=20–40$ denoise steps, horizon $H=8$ actions, control loop ≈1–5 Hz when run on a desktop GPU.
Why It Works (Strengths)
- Handles “many right answers.” The distribution can branch (pouring sauce clockwise or counter-clockwise), then sampling picks one branch instead of averaging them into nonsense.
- Scales with DoF. Diffusion models routinely juggle million-pixel grids; a 30-DoF arm trajectory is tiny.
- Stable training. Plain score-matching, no adversaries, no negative sampling tricks.
- Built-in short planner. Predicting eight future steps every frame gives local foresight without a separate MPC.
Benchmarks confirm the hype: 15 RoboMimic + FrankaKitchen tasks, +46.9% average success over IBC, LSTM-GMM, etc. DP paper
Limitations & Pain Points
| Pain | Root cause | Real-world impact |
|---|---|---|
| Inference latency | 20-40 gradient steps per control cycle | ~1-2 Hz closed-loop rate on a single GPU, too slow for contact-rich tasks. |
| Responsiveness vs. consistency | Needs an 8-step horizon to avoid mode hopping | Robot may over-commit if the environment changes abruptly. |
| OOD blindness | Pure behavior cloning; no self-uncertainty | Robot silently drifts when it leaves the demo manifold. |
| Data/compute hunger | Hundreds of clean demos, >10⁷ params | Expensive on real hardware or embedded CPUs. |
How the Community Is Fixing Things (2024-25)
| Approach | Key idea | Win |
|---|---|---|
| One-Step Diffusion Policy (OneDP, 2024) Zhengdong Wang et al. | Distill the $T$ step sampler into a single forward pass | 62 Hz control instead of 1.5 Hz → real-time pick-and-place. |
| Consistency / ManiCM (2024) Guanxing Lu et al. | Enforce consistency along the diffusion ODE; training predicts the final answer from any noise level | 10× speed-up, still hits 30+ simulation tasks. |
| Responsive Noise-Relaying DP (RNR-DP, 2025) Pang et al. | Maintain a noise buffer: head is clean (executes), tail is noisy (keeps plan smooth) | Recovers responsiveness without shrinking horizon. |
| Diff-DAgger (2024) Ye et al. | Use high diffusion loss as an uncertainty signal to trigger human corrections | 14% higher success on out-of-distribution scenes. |
| Large-Scale Diffusion Transformer (2024-25) Chen et al. | Scale to 1B params with factorized embeddings | Better cross-task generalization on Open-X Embodiment. |
Surveys (TechRxiv 2025) synthesize these trends Survey 2025.
Open Questions (Research To-Do List)
- Sub-millisecond sampling. Can we hit 500 Hz on an ARM SoC? OneDP is a start; neuromorphic variants like Spiking DP SDP 2024 are tantalizing.
- Truthful uncertainty. Beyond Diff-DAgger, how do we fuse epistemic (data) and aleatoric (sensor) uncertainty without killing multimodality?
- Task transfer. Can a single DP backbone master hundreds of tasks with minimal fine-tuning? Hierarchical DP HDP 2024 hints at one path.
- Multi-modal inputs. Stable fusion of RGB-D, force torque, language prompts is still clunky. ManiCM’s point-cloud conditioning is a promising demo.
- Safety & constraints. How to project diffusion samples onto a safe set (joint, wrench, collision) in real time?
Practical Pointers
- Code: https://diffusion-policy.cs.columbia.edu (original) https://research.nvidia.com/labs/dir/onedp/ (OneDP) Official PyTorch & Isaac Gym examples.
- Colab quickstart:
# Sim training (RoboMimic Lift)
python train.py --task=lift --horizon=8 --n_steps=40
# Real Franka robot inference
python control.py --checkpoint=weights.pt --camera=rsp
- Data: RoboMimic, Meta-World, FrankaKitchen, plus your own teleop logs.
Takeaways
Diffusion Policy = denoise your way to robot skill. It unlocked a clean, generic recipe for multi-modal imitation and is now the reference line every new paper must beat.
But like early GANs, it’s slow, assumes the world matches the demos, and ignores safety. 2024-25 research slashed sampling time, added uncertainty gates, and pushed toward larger, more universal models. Expect the next wave to fuse language, tactile feedback, and hard constraints, giving robots that can improvise safely and quickly.
If you’re scouting for thesis topics, the treasure map is right above.
References
- Cheng Chi et al., “Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,” arXiv:2303.04137, 2023.
- Zhendong Wang et al., “One-Step Diffusion Policy,” arXiv:2410.21257, 2024.
- Pang et al., “Responsive Noise-Relaying Diffusion Policy,” arXiv:2502.12724, 2025.
- Lu et al., “ManiCM: Real-time 3D Diffusion Policy via Consistency Model,” arXiv:2406.01586, 2024.
- Ye et al., “Diff-DAgger: Uncertainty Estimation with Diffusion Policy,” arXiv:2410.14868, 2024.
- Chen et al., “Diffusion Transformer Policy,” arXiv:2410.15959, 2024.
- TechRxiv, “Diffusion Models for Robotic Manipulation: A Survey,” 2025.
- Li et al., “Spiking Diffusion Policy for Robotic Manipulation,” arXiv:2409.11195, 2024.
Technical Terms Glossary
- Aleatoric uncertainty: Uncertainty arising from inherent randomness in the system or observations
- ARM SoC: System on a Chip based on ARM architecture, used in mobile and embedded devices
- Behavior Cloning: A technique where an AI directly copies human demonstrations
- CNN: Convolutional Neural Network, specialized for processing grid-like data (images)
- Diffusion Model: A generative model that learns to gradually denoise random data
- DoF: Degrees of Freedom, independent parameters defining a system’s configuration
- Epistemic uncertainty: Uncertainty due to lack of knowledge or data
- GAN: Generative Adversarial Network, a type of generative model with competitive training
- GPU: Graphics Processing Unit, specialized for parallel processing
- IBC: Implicit Behavioral Cloning, learns by comparing action pairs
- LSTM-GMM: Long Short-Term Memory with Gaussian Mixture Model, predicts action distributions
- MPC: Model Predictive Control, optimizes actions using future predictions
- ODE: Ordinary Differential Equation, involving one variable and its derivatives
- OOD: Out-Of-Distribution, situations different from training data
- RGB-D: Color images plus depth information
- ViT: Vision Transformer, applies transformer architecture to image processing